Note
Implementation guide for DAX Webservices.
1 Abstract¶
This document outlines the purpose, reasoning, and suggested implementation of the DAX Webservices. The DAX Webservices are the way to get LSST data through a set of (primarily) IVOA-compliant services that will allow any tool or client supporting IVOA standards to query and retrieve data.
Within the context of the LSST Science Platform (LSP), the DAX Webservices are the key component of the LSP’s API Aspect, are the principal means for making LSST data available to the Portal Aspect, and play an important role in supplying LSST catalog data to the the Notebook Aspect.
2 Having Standards¶
The purpose of the DAX Webservices is to provide an IVOA-compliant interface to access LSST data, both catalogs and their metadata (including semantic annotation and provenance), and images and their metadata (including observation records and provenance)
In the DAX Webservices, we are taking the LSST tools and stack, and exposing a view based on network protocols that IVOA-compliant tools can use. The underlying LSST tools include technology like the Butler for finding data (e.g., FITS files) on disks, managing associations between datasets, and serialization of the LSST Python object model; the Science Pipelines code for astronomical computations; and our distributed, spatially sharded database, QServ, for querying our primary astronomical catalogs.
The Butler and QServ are purpose-built to meet the requirements of the scientific processing and analysis of the LSST dataset, and yet are designed to be generic and applicable to other dataset. However, they are not designed to meet the IVOA standards, and they do not themselves provide Web services. They will serve as the underpinnings of our implementations of the Web services, however, as well as fulfilling their other roles in supporting production pipelines and individual scientists’ investigations.
The fact that they aren’t webservices means they rely on things like POSIX file permissions on local disk mounts, and are running already in a specific user context. Webservices operate differently, for example taking auth headers in each request to verify permissions. The DAX Webservices will provide such a wrapper to run a service, utilizing not only Butler and QServ, but other local services, to provide an IVOA-compliant interface for clients.
Many times, the DAX Webservices will use the LSST Science Pipelines’ specific toolchains to back the processing of requests. For example, to do image cutouts, the image service will likely need to use the Butler to find the persisted calibrated images (single-epoch PVIs or coadds), then use the Science Pipelines to do cutouts and other operations on the images, before sending them back in the format required by the IVOA protocol being used.
For IVOA-compliant catalog access, the standards revolve around TAP (Table Access Protocol) and VOTable to represent the results. The language of TAP queries is the IVOA-specified ADQL, which is based on SQL92 with significant extensions to support spherical geometry. The underlying SQL variant has some differences with the native ones of the databases used in LSST’s QServ system, as well as in the project’s more conventional (currently Oracle) RDBMS systems. The DAX Webservices must rewrite the ADQL queries appropriately to match the native SQL dialect and translate the spatial extensions to QServ’s native spatial functions before dispatching them to QServ and awaiting the result. QServ also has a specific way of handling long-running asynchronous queries (“shared scans”) which must be translated to the query lifetime management model of the IVOA standards.
In the following sections, I will outline the standards we intend to implement, how we might implement them, and where the tricky parts may be.
2.1 Why are standards important?¶
Astronomers have been writing code for quite a long time. In the era of multi-messenger astronomy and cross-referencing datasets of multiple instruments, one way needed to be created to standardize access to the data. Otherwise, every time a new telescope is created, owners and maintainers of astronomy tools would have to add support for the new telescope, taking into account the idiosyncratic nature and interfaces of that particular instrument.
By providing one standard way of doing it, we allow for one tool to use data from multiple instruments. We can also use tools developed before LSST, unchanged, to access LSST data if we want. This allows for astronomers to have working, tested tools before our telescope is even ready for this level of integration testing.
There are many things about the standards that I find confusing, or disagree with. But like the law, the standard is the standard. I’m no fan of XML, but it is better to support the standard and not love it, than try and break bad.
Each time the standard is not followed, there may be features or unintended consequences in 3rd party tools. For example, if an unknown state was returned from an API, or a required key was missing, each tool will respond and error in its own way. Some may stop working, some may ignore it, some may outright crash or throw an exception. Tools differ in their access patterns even using a standard, so we also need to do compatibility testing with tools we want to officially support for our users.
We can do things above and beyond the standard, but we should know that those things cannot interfere with what is stipulated by the standard. Some additions may be nice, but these must be measured against the impact of implementing more of the IVOA standards, which will be used by more tools rather than just our custom LSST tools.
Because of the importance of our data to the community, and the unprecendented scale of the dataset, LSST is in a position to work with the IVOA to evolve the standards over time when we find that they don’t meet our needs.
2.2 What standards do we want to support?¶
We will implement an interface that supports the following standards. Links are provided to give a reference set of versions to allow people to communicate about sections and page numbers of each particular specification:
Catalog oriented standards:
Image oriented standards:
- ObsTAP and ObsCore
- Server-side Operations for Data Access (SODA) 1.0
- Simple Image Access (SIA) 2.0
- Hierarchical Progressive Survey (HiPS) 1.0
User storage standards:
Underpinnings:
- VOTable 1.3
- Universal Worker Service (UWS) 1.1
- Data Access Layer Interface (DALI) 1.1
- IVOA Support Interfaces (VOSI) 1.1
If you don’t know what these standards are or how they fit in, don’t worry! In the Services section, I will outline where each of these come into play.
2.3 What clients do we want to ensure compatibility with?¶
Some clients and tools are just part of the general ecosystem of astronomy tools. We will need to support them. We will also be building the SUIT (LSST Science Platform) on top of many of these services. The portal and the notebook aspects will both be calling the services, and possibly passing IDs to async results between them.
Here’s a list of clients:
- Science Platform / SUIT
- Tool for OPerations on Catalogues And Tables (TOPCAT)
- Aladin Desktop
Note that the LSST requirement for authenticated access to all data (discussed further below) is exploring an area that is not well-supported by existing tools, and that does not have a clear community consensus on the choice of standards. As a result, LSST expects to have to work with the external tool community to help them make their tools capable of working with our authentication system and be able to access our data.
We also wish to facilitate other astronomical archives in making the LSST data accessible, via IVOA-standard interfaces, through their portals, so that it can be used in conjunction with other datasets of value to the community. Similarly, a virtue of building the LSST Science Platform’s tools, such as the Portal Aspect and the Python interfaces in the Notebook Aspect, around IVOA standard is that this enables those tools to be used to bring in additional data to the Science Platform environment.
3 Architecture¶
3.1 Diagram¶
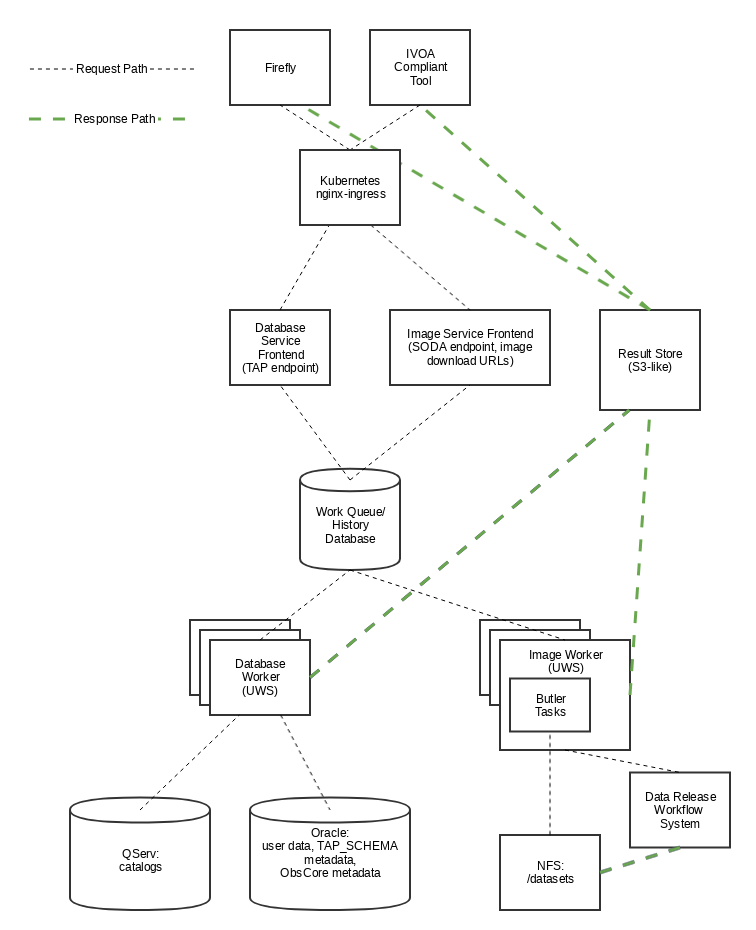
Figure 1 Architecture Diagram for DAX Webservices.
3.2 Call Flows¶
3.2.1 Catalog Query¶
(Based on the asynchronous flavor of the TAP interface.)
- Caller submits an ADQL Query to the TAP service endpoint via HTTPS POST and receives a query ID to check for results.
- Database service parses the query to determine the back end for the query, based on the tables selected, and translates the ADQL to the back end’s native query language.
- Request is created and put on the work queue.
- UWS worker dispatches the query and gathers results.
- Worker massages data into the requested format and marks the request complete.
- Caller uses the URL and ID to be redirected to the results file.
3.2.2 Catalog Metadata Query¶
Same as a normal catalog query, but the query uses the TAP_SCHEMA tables stored in the Oracle database.
3.2.3 Image Metadata Query¶
Same as a normal catalog query, but the query uses standard tables that contain image metadata stored in the Oracle database. An image metadata query can be a normal ADQL TAP query against the native LSST metadata, or against LSST’s CAOM2 data model tables. It can also be an ObsTAP query (i.e., ADQL against the basic table defined in the ObsCore standard), or it can be done via the simplified SIA protocol. In each case, the result is a VOTable with image metadata and corresponding access URLs.
3.2.4 Image Retrieval¶
- Caller uses an Image Metadata Query to determine images they want to retrieve.
- Caller makes another HTTPS GET to the URLs returned from the Image Metadata Query.
- Image Service creates a ID, and puts the request on the work queue.
- Image Service Worker picks up the request and uses the Butler to see if that file exists.
- If the file does not exist, but is recreatable as a virtual data product from underlying data, the Image Service recreates that file by using the workflow engine to execute the appropriate Science Pipelines code.
- Once the file exists, the file is put in the object store and the worker marks the request as complete.
- Caller is redirected to the object store URL.
3.2.5 Image Cutouts¶
- Caller uses an Image Metadata Query to determine datasets and particular images they might want cutouts of.
- Caller makes a SODA request to the Image Service with parameters that determine positions and shapes of cutouts.
- Image Service creates an ID and puts the request on the work queue.
- Image Service Worker picks up the work and uses the Butler to gather and create image files it needs to process the request.
- Worker uses the appropriate Science Pipelines code to create cutouts on those images.
- Worker uploads result to object store and marks request as complete.
- Caller uses the ID to check for results, and is redirected to the object store URL of the result.
4 Database Service¶
4.1 TAP 1.1 & VOTable¶
For querying the catalog that is hosted in QServ, we want to support Table Access Protocol (TAP) v1.1. As outlined in the spec, TAP is a standard interface to execute a query (specified as ADQL) and return a table (usually VOTable) with the results of that query.
When the results are returned in the IVOA standard VOTable format, the service can provide extensive metadata about the columns and datatypes in the table, as well as the data values. This metadata can then be used to provide intelligent behavior in client tools and libraries. This is planned to be exploited in the LSST Science Platform.
In order to run queries, we use the /sync, and /async endpoints,
which are required parts of TAP 1.1.
There are other optional endpoints
in the spec, such as /tables, /examples, and /capabilities.
For a chart that contains what is required reference page 10 of the
TAP spec.
Because of the size of the query results expected for the LSST data and the comparative verbosity of the VOTable data format, LSST has explored offering a more efficient structure and table payload format than those available in VOTable, possibly involving the use of JSON for metadata and special file formats for the bulk data. However, LSST must in any event support VOTable for compatibility with the standards and with community tools.
4.2 Sync, Async, and UWS¶
According to the standard, we need to provide endpoints to run queries
either sync or async.
These endpoints may be named /sync and /async or may have other
names, especially in the case of authenticated services, as long as
they are documented in the service’s self-description.
For queries submitted to a sync-like endpoint, the service blocks and
waits for the response to return to the caller in the response.
For async-like queries, the service is required to return an ID that
can be referenced in the future to determine the query status and
obtain its results.
This is particularly useful for long running queries where the query
may take hours to run, such as QServ shared scans.
The UWS standard provides the details on how to structure the endpoints that provide the ID and allow further interaction with it. While the UWS standard does not specify how to run the jobs, it provides a RESTful way of accessing the state, checking results, and providing control over jobs, such as canceling.
The LSST Science Platform design expects to make heavy use of asynchronous queries in order to permit queries to be launched from one of its Aspects and then located and accessed from another Aspect.
4.3 TAP_SCHEMA¶
The IVOA standards try to not only standardize access to data, but also the discovery of that data. Section 4 of the TAP 1.1 spec outlines TAP_SCHEMA, which is required of TAP 1.1 implementations. The idea is for a caller to be able to discover the schema of the data available for query (tables, columns, data types, and cross-table relationships) to craft their queries correctly. This supports the construction of client tools that can provide a user-friendly query front end to any properly self-documenting TAP service.
The subsequent parts of section 4 of the TAP 1.1 spec (4.1, 4.2, 4.3, 4.4) outline the schema for the metadata database tables that provide this service self-description.
To use this part of the service, you can submit a query through TAP, against metadata tables whose names and column structure are specified by the standard. The results are returned in VOTable format like any other query. In this clever usage, we can have one transport to tell us about the metadata as well as the data itself, using ADQL to query the metadata.
The population of the TAP_SCHEMA tables from the LSST data model is itself a non-trivial task. The “Science Data Model” work currently in progress may result in a machine-readable version of the data model which could be parsed to yield the appropriate content for the TAP_SCHEMA tables.
4.4 LSST Specific Requirements¶
While not covered generally by any IVOA specific standard, there are a few things that we have as requirements that are more LSST specific.
4.4.1 QServ¶
QServ is our custom scalable database for distributed hosting of data release catalogs. QServ is based on top of MariaDB with customizations to support efficient queries against spatially organized data in spherical geometry. QServ has some special performance characteristics, but from the perspective of the DAX services, it means we mostly need to be compliant with its SQL variant and its geometry functions, and be able to transform ADQL into QServ SQL. QServ also has special functionality to do full table scans, allowing multiple queries to be run simultaneously (“shared scans”), support for fault-tolerance through maintaining redundant copies of the distributed data, and some special endpoints to allow for queries to run async with users able to retrieve the results later on.
Tables in QServ can either be “spatially sharded”, with their content distributed across its many database workers according to a tiling of the two-dimensional sky, or, for smaller tables, replicated across all workers. Tables of both types can be combined in JOINs, but spatially sharded tables can only be joined “locally” within shards, supporting the query of relationships between spatially nearby catalog entries.
4.4.2 No JOINs Across QServ and Oracle¶
While TAP will present the tables from QServ and Oracle as one large unified table space, we can’t allow for people to do SQL JOINS between them.
If we wanted to support this, it would be very complicated, so for now this is out of scope. If you need to do some joins, query each table with a different query and then JOIN it yourself by iterating through the data on the application side.
JOINs should be supported on all Oracle or all QServ tables though. Just JOINs between them will be disallowed.
In order to partially work around this restriction, certain tables, including for example key image and visit metadata tables, are expected to be made available in both database systems. This facilitates their use in JOINs in both contexts.
4.4.3 Authentication and Authorization¶
The primary released LSST data will not be world-public at the time of release (see LPM-261 for more details). In addition, scientists may have their own private datasets uploaded as well to do JOINS or other algorithmic analysis against. We need to be able to authorize each user to use the LSST DAC resources as well as protect their results and query history from someone else trying to scoop their research. Many IVOA standards come from the era of public astronomy data, so although there is some support for authentication and authorization in the standards (e.g., in the “Single-Sign-On Profile: Authentication Mechanisms” document), there may be some excitement here trying to add AAA to everything.
Note
AAA needs a lot more work and deciding on hard requirements
Since we are using UNIX groups and other very POSIX level permission schemes, we need to figure out how to respect these things in our Webservices, which aren’t always impersonating the user. For example, to get a result file, it’d be much easier to check the permissions rather than try to su to that user, and see if they still have access (which brings in things like ACLs, and UNIX group mechanics). Depending on the level of auth required, we might be able to restrict this to the creator of the query, rather than their group. Either way, this will have to be determined.
4.4.4 History Database¶
We want a history database of queries that can be looked through. The UWS spec defines that there is a way to get a list of jobs, both pending and finished, so that is one way of accomplishing this goal. Depending on how long we want to persist this data for, we might want to back up the queries, and index them in some other interesting way, probably through some other kind of ancillary service.
Query text should be protected by auth to only allow a user to see their own queries.
Retention of a history entry does not imply retention of the results of a query. We expect to retain query results for a relatively short time, both to facilitate users in obtaining results from long-running queries without setting an overly narrow window for them to respond to a notification of a completed query, and to enable workflows that begin in one LSP Aspect and continue in another. However, we expect to retain query texts and other records of the execution of a query for much longer, possibly unlimited, periods. The UWS standard on which the TAP protocol rests makes provision for this situation by defining an ARCHIVED state for queries post-execution in which the query results are no longer available but other information, including the query parameters, is retained.
Note
It is not clear what to do about retention of the tables supplied by users via the UPLOAD parameter of the TAP service, as these could be very large, yet in a formal sense are part of the query specification.
The existence of the history database serves a number of purposes in the LSST Science Platform:
- It is useful in its own right for users to be able to understand the evolution of their data accesses.
- It provides one of the two means of transfer of a query workflow from one LSP Aspect to another; users can perform actions such as “show me the results of my last query”, or review recent queries, in order to find a query started in one Aspect in another Aspect.
- It provides support for the repetition and reproducibility of queries. Of particular interest for the continuously evolving Prompt data products, the information in the query history database enables a user to re-run a query either so as to reproduce its results as if at the time of the original query, or to re-run it afresh including newly released data.
4.4.4.1 History editing¶
It may be useful to provide a means for users to mark history entries, such as those from queries that turn out to be mistakes or otherwise not useful, as “hidden” (from themselves) in order to make it possible for a default display of a query history to be “clean” and populated only with worthwhile entries. It would also be useful to allow the metadata queries performed by the LSP Portal Aspect as part of its self-configuration to be hidden by default, as it is possible that its activities may generate large numbers of small queries, particularly against the TAP_SCHEMA tables. This may suggest that at least a three-level “visibility” parameter may be appropriate for the query history database (normal, user-hidden, system-hidden), though in all cases users should be able to see their entire history upon explicit request.
4.4.5 Large Result Sets¶
Since LSST queries may take a long time to run, and have large results sets, we need to be able to cache large results sets (up to 5 GB of results per query) for a reasonable period of time so they can be retrieved. This may be on the other of a few days or a week, since some of the queries may be run overnight or over the weekend.
These results must also be protected so that only the user executing the query can retrieve the results. After the results are retrieved, that user can obviously do what they will with the results (such as share them). While there are data rights implications here, once the data is out of our control, it’s out of our control.
4.5 Implementation¶
Now that we’ve established the particulars of what we want, let’s dive into the implementation of this service now.
This service needs to:
- Accept queries through a TAP-compliant HTTPS interface.
- Record the query in the query history.
- Determine what backend those queries should be dispatched to.
- Rewrite original ADQL query to the SQL variant of the backend.
- Dispatch the query, either locally or through a pool of workers.
- Gather results from the query, and transform them into VOTable.
- Put the results in a place that the user can download.
4.5.1 TAP-Compliant Interface¶
There are many ways to write a webservice these days, including many frameworks. We know what URIs we want to serve, /sync and /async, and that we want to serve results in XML. We need to really reference the TAP 1.1 spec for this part, implementing what we need to, such as parameters (LANG, QUERY, MAXREC) as well as wrapping the results in a VOTable format.
4.5.2 History Database¶
Note
We still need firm requirements on what the retention period and auth scheme should be for accessing the history database.
There are many data stores we could use for a history database. Many might even be tied to the execution of async jobs. For example, the distributed task framework celery uses RabbitMQ, Redis, MongoDB, to store results and execution status. This isn’t just used to query the history but to drive execution. These databases can also be queried directly by users, or we can add additional URIs to look through the history.
The UWS spec also mandates a way to list jobs, and get their results. This is fairly analogous to the history database functionality we want, as it lists the queries, their IDs, execution status, and result location. It may be useful to structure a more general query-history-query service in a way that returns the same basic data structures as the bare-bones UWS job list.
4.5.3 Determine the Backend¶
Many specs use the TAP and VOTable standards as a way of transmitting complex data. For example, the TAP_SCHEMA tables store the semantic metadata, and could be on a different backend than the catalog itself, which is hosted by QServ. Some user generated (Level 3) data might also be present in another database, such as Oracle or Postgres. There are also special tables for ObsTAP to look at image metadata.
The tricky part here is that if one database isn’t hosting all the tables, we need to inspect the query to determine what tables are being accessed, and then route the query to the appropriate backend. Different backends might also have different load characteristics, such as the number of running queries.
4.5.4 Query Rewriting¶
QServ doesn’t speak ADQL. Neither does Oracle. We need to take the ADQL query, inspect it, and rewrite it to work on the individual backends.
This may be to work around various quirks of different SQL variants and implementations (such as how keywords work, or the way of limiting results, or datatypes).
There are also some extensions to do very astronomical things, such as cone and other spatial searches, as well as dealing with different coordinate systems. Different back ends may have very different ways to implement these spherical geometry constructs.
4.5.5 Query Dispatch¶
Once we have the final query and we know where it’s going, we are ready to send the rewritten query to the backend and start getting the results. Since these results may be very large (GBs) or very small (0 or 1 rows), we need to be able to support both cases in a performant way.
For sync queries, the caller simply waits on the HTTP connection until the results are available. For async queries, since the caller will make another request, we need to ensure that these requests will always find the results, no matter how many TAP service copies we have. This means we can’t really store results locally on the TAP service disk (also this has the possibility of filling up the disk). It is better to have a central disk or shared place, so that results can be written there, and then picked up by anyone handling getting the results. This also helps with keeping results through upgrades and transient failures.
It’s also a good idea to separate out your front ends (things taking HTTP requests) from your back end workers (which dispatch to the database). This allows for a more even distribution of load across the workers, and keeping the load on the backends (which don’t scale as easily) in check.
As we gather these results, we need to put them also in the right format, which is VOTable. This may involve some coercing of data types to VOTable data types, rather than the original backend. Once the result is written and in the correct format, we can record that the query is finished and the results are available. The “Science Data Model” and its record of the intended data types of the catalog data may be of use in determining the correct VOTable data types to be used, rather than simply inferring them from the underlying database data types.
Note
QServ also supports an async query mode. We should investigate this to determine where it fits in with our plans. Inevitably we will have to gather the results, and put them in an IVOA-compliant format.
Note
We need to figure out how to properly impersonate the user making the request. Do we store their token, or use a service account and su to them?
4.5.6 Centralized Result Store¶
After the user has completed their query, they will want their results, which may be large. They may be downloaded more than once, so we likely want to keep the results sets around for at least a few days, to prevent needing to rerun the same query on the database.
Because of the diversity of queries and their results sizes, and not being able to know the size of the results from the query, we need to be careful about local resources. If the results were stored on the TAP service nodes, we could easily fill up the local disk, which may be as few as 20 results for 100 GB. The fragmentation of splitting the load across multiple TAP service nodes might also be bad, since the sizes of the results might be uneven, filling up some nodes and leaving others empty. We want to store all these in a central place, preferably with URL access, so we can serve the results file directly off disk.
By having one place store the results, we eliminate the problem of the client needing to contact multiple servers to find the results, or the results not existing by the time the user checks for the results.
This could easily be an S3 like object store, or an NFS volume with Apache or another web front end checking for auth on top. Given that it is simply serving up static files, this part should be relatively easy.
4.5.7 Performance, Load, and Failure Characteristics¶
The performance characteristics of the database server should be fairly straightforward, at least compared to what it is built on top of and completely depends on.
The overhead of processing a request, parsing the query, putting it in ADQL, and dispatching it to the server should be very quick compared to running the query. This time should be fairly constant no matter what the query is.
Running a query is completely dependent on the query (which we don’t control) and the database (which we depend on, but don’t control). Things like the load on the shared database resources from other users and other queries can’t really be predicted.
The DAX Webservices can be good stewards of these shared resources. By having a work queue with a consistent maximum number of queries in flight, we can provide an orderly way to access a limited resource, without overloading it. There is usually a sweet spot in terms of performance, where you are fully using your resources, but not thrashing, that we will hopefully discover and tune our system accordingly.
The overhead of processing the response is certainly higher than that of the request. Having to take an up to 5 GB file and transmute it from database rows into a VOTable or other format can be costly. The latency involved in such large transfers is also not to be ignored. Given that we know we have a 5 GB limit on query responses, we can ensure that our portion of the processing of the results will generally have a fixed upper bound.
Because the database service doesn’t have much internal state, and has no important data to lose, the failure characteristics are straightforward. We might fail the request, and have to retry it, or lose a result. Since we cannot keep all results for all time, it’s inevitable that some results will be unavailable after a period, and tools will simply rerun the query. Transitive failures can be retried if desired, but not required.
5 Image Service¶
5.1 ObsTAP¶
ObsTAP is the way to query and determine metadata about image data. By using the same TAP / VOTable infrastructure from the database service, a user or client can craft a query against the available metadata to discover what images exist that fulfill those criteria, and retrieve the URL to access them.
The types of queries that can be run are independent of the data being served - the standard dictates what tables and columns must exist to run queries against. This helps general discoverability, as otherwise those tables would have to be described first (probably through TAP_SCHEMA), but by having a uniform data model, this allows one query to be run against multiple ObsTAP endpoints and have it work everywhere.
In the ObsTAP spec, there are some great UML diagrams for the data model on page 13-15. Then the data model is expanded further with tables describing the database metadata. Table 1 has all the metadata that is absolutely required, containing the usual suspects such as observation id, time, type of data, ra, dec, are all there. Section 4 on page 20 actually has the TAP_SCHEMA minimal set of fields and their datatypes that can easily be dumped right into TAP_SCHEMA.tables.
For some of these fields, we will have one identifier that is present throughout, and mostly constant, such as instrument and type of data (image). For fields that change, such as RA/DEC, we will need to present that as a database table. This can be the same backends that the Database Service uses for TAP_SCHEMA and other associated metadata.
Two important basic fields are the access_url, and the access_format. This tells the client what URL it can go to to retrieve the image, and what format (JPG, FITS) the image at that URL is encoded in. The format column is a string containing a standard MIME-type.
Along with image metadata, ObsTAP also supports serving and querying provenance data, although it is not required.
Note
Are we going to use ObsTAP to serve provenance data?
5.2 SIA¶
SIA (Simple Image Access) is a simpler way than ObsTAP to discover images based on parameters the caller provides. This isn’t done in ADQL, but via a smaller list of parameter options. The SIA metadata model is the same as the ObsCore data model, and if we have a database of the ObsCore data model, it should be easy to field SIA queries against it.
The types of query parameters of SIA are things like position, energy, time, and wavelengths. There is a list of parameters in Section 2.1 of the SIA spec, that outlines all the possible query parameters.
SIA, unlike TAP, ObsTap, and SODA, only provides a sync endpoint called query, which takes a query string or post parameters, and returns a VOTable consistent with that of ObsTAP responses (Section 3.1 SIA spec). The sync nature of the request/response is to retrieve a VOTable response, containing links to the images, not sync/async about image retrieval. This will be related to a point mentioned below about PVI availability.
5.3 SODA¶
SODA (Server-side Operations for Data Access) is an IVOA standard that covers the processing of server side image data before returning it to the caller. Since many of our image files are large, and the portion of the file that the caller may care about is small, this makes sense to be able to filter the data down on the server side to reduce the amount of data transferred, along with the latency and cost of such a transfer. Another common use case is to create a cutout that covers multiple raw images (such as PVIs) to create a mosaic image that has the cutout and has stitched together the edges of the individual images to create one seamless image.
By allowing a user to select positional regions using the POS argument, different regions can be selected, such as CIRCLE, RANGE, and user defined shapes via POLYGON. To find the image with the correct filter, the user can use the BAND parameter, to provide a range of wavelengths to return.
Like the TAP service, SODA specifies a sync an async resource, of which you need at least one. Async behaves as a UWS service, just like TAP, and can provide an ID that can be later retrieved for large result sets.
Depending on the arguments, one query can provide multiple image results, for example looking at multiple bands, or drawing multiple CIRCLEs.
Note
It looks like SODA allows for us to also do our own custom parameters, to allow for more operations to happen. Other than the cutouts defined by the spec, what server side transformations do we need?
5.4 LSST Specific Requirements¶
5.4.1 Images we are serving¶
The standards mentioned previously can be used to host any particular image data, from any instrument. For LSST, we have two types of images we’d like to serve through these endpoints and queries:
- PVIs - Processed Visit Images
- Multiple sets of coadds - Created by Coadding PVIs.
Each of these will have images per band, and covering the LSST footprint. There are also multiple different sets of Coadds using different addition methods and selections of raw data.
Note
How to multiple data releases come into play when handling image metadata? Should this be a different dataset id?
5.4.2 PVI Retention and Virtual Products¶
Due to cost and space constraints, the current plan does not involve storing all the PVIs on disk. There is only a 30 day moving window of availability for these images while they are processed and can be easily read off disk.
After this 30 day window, additional work would need to happen to be able to recreate the PVI file, which could then be served to the caller. This work would involve having to read off tape (or hopefully, a disk) the raw image components, then use the workflow system to tell it to create the PVIs. While most of this logic is out of scope of this document, the important point is that this may take minutes and possibly even hours before an image can be served.
This is also true of other processing intensive operations, such as looking at different sets of coadds that might not always be on disk.
Because of these reasons, doing anything with images synchronously is probably a bad idea.
5.4.3 Authentication and Authorization¶
Users will have to be authenticated, and authorized (with data rights) to query these services and retrieve image data. This security model may be simpler to that of the TAP service, because people will likely not be uploading their own images to be served by the SIA, SODA, or ObsTAP interfaces. This means that there is generally a consistent level of protection needed that does not vary per user - everyone has the same access to all the image data, as all the image data is covered by LSST data rights rules.
That being said, ObsTAP does support a field called data_rights, which allows us to say that our dataset is either public, secure, or proprietary (ObsCore B.4.4). This will likely be one flag per data release, which will either be proprietary, then public after it is released.
5.4.4 History Database¶
While it is not mentioned in the requirements, we might want to extend the idea of the history database to encompass queries to the image service, such as ObsTAP, SODA, and SIA queries. Because of the authorization model outlined above, the results are less likely to need to be secured between users, allowing for caching and result reuse to be higher and easier to accomplish in a secure manner.
Either way, we will want to audit the access logs to this service, and attempt to determine usage patterns, to improve performance.
Note
What are our requirements for public history of image requests?
5.4.5 Large Result Sets¶
Because of the large size of the LSST data, including the images, we will want to ensure that queries are limited to a reasonable number of results, to not put undue load onto the system.
Since we have to support async queries to SODA, and because those jobs may take a while to run, it makes sense to use the same centralized results backend to store the data and provide URLs to objects in that backend.
5.4.6 Image Metadata¶
There will be a visit table that contains all the visits, and metadata about PVIs. This would be ideal if it’s in the ObsCoreDM format so it can directly be queried against using ObsTAP. Even if it’s not exactly in the same format, we’ll need to provide some kind of ObsTAP-compliant view of that data to allow for queries, since the metadata model has to be in a specific format to follow the standard.
We will also need tables that contain the metadata about all the coadds, so they can also be discovered, even though it’s not a visit at all, and therefore doesn’t belong in the visit table. We might have to virtually stitch these two tables (one containing PVI metadata, and one containing coadd metadata) together somehow to allow a unified interface for querying through one table.
This metadata also needs to exist for things that aren’t currently on disk, because they are virtual products. The fact that they exist in this database lets us know that they can be created, and at one time, were created. When someone queries these products, we need to create them on demand.
Note
The current definition of the visit tables are on Github
More time should be spent making sure that we have everything we need in the visit metadata.
Note
How are we currently planning on doing coadd metadata?
Seems like we might want to use a different dataset ID to refer to coadds, as that is how SODA determines what raw images to use?
5.5 Implementation¶
5.5.1 Querying Metadata and Image Discovery¶
Some of the implementation here gets to be shared with the Database Service, as ObsTAP is making sure that certain tables exist in a certain format and can be queried from our TAP service.
First, we need to ensure that we have the proper metadata, and it is available via the standards-compliant queries. Then we use the same TAP service described as above, using its sync or async endpoints to retrieve a VOTable containing image metadata. This image metadata contains URLs that can be used to access these images.
For SIA compatibility, we can run this on top of the current ObsTAP implementation because for each SIA query it can be mapped into an ObsTAP query, and the response is of the same format (VOTable). SIA only supports sync though, so it should only be for short queries. Again, the sync part is only relating to the query, but the images might also not be available for some time, even if there is an access_link provided in the response. This may break SIA clients.
5.5.2 Retrieving Images¶
Now we know what images exist, the types and formats of those images, and we have URLs to query them. Now we can either download PVIs or coadds, or do server side processing such as cutouts to receive a processed image via SODA on those PVIs or coadds.
Both of these types of requests can be served by one service, and that server uses the Butler as its backend for retrieving images and doing simple processing such as cutouts.
If the URL presented is not a SODA request, we can say that this is a request asking directly for a full image (either PVI or Coadd). We use the URL to map this back to a way that the Butler can retrieve the image using its known mappings. Once we find the file on disk (or network disk), we serve it up directly to the user. If the file doesn’t exist, we can create it using the workflow engine, but the image might not be available for some time. For direct GETs, we might need to use HTTP control to tell it to try again later, and that the image isn’t ready yet. Most of the standards assume images are all accessible in short order if they exist in the metadata.
Note
For direct image access without processing, standards assume files are available immediately, how do we do this async?
If the URL is a SODA request, then we get to work. First, we process the query and pass the parameters to the Butler, which will find the images, stitch them together, and attempt the cutout. This may take time, because the PVIs or coadds virtually exist, be a request that covers a large space, or has multiple cutouts requested.
SODA allows for async operations though, so we know we can tell our caller to call again later to get their result no matter how long it takes.
Because the resulting files can be large, we can upload or copy them to shared storage in an object store, and have the image server redirect HTTP requests for finished work items to their URL in the object store. In this way, we can split up the workers and the servers and scale them up and down independently.
5.5.3 Performance, Load, and Failure Characteristics¶
For the image metadata portion of the system, these queries will be run against the TAP service, and have the same performance and load characteristics as noted in that section.
For the image retrieval and processing portion of the image service, we have it a bit easier. Much of the performance will be related to the speed of access to images, and if they already exist or are virtual products. For the files that exist, we will need to copy them off of a network share, which is a shared resource, which could be a bottleneck under heavy load.
Processing for creating virtual products will likely involve the workflow engine, and having to be queued and executed there. This is also a shared resource, so depending on load from other portions of the system, this could be slow and add latency to the end user.
For processing cutouts and doing mosaics, we will likely use the Butler and local CPU processing to create those products. This means we need to provision the CPU correctly - not too small so that big jobs take a long time, but not having a lot of unused resources on a worker. If we have workers that have too much CPU, we could always reduce the CPU requirements for each worker and have more workers to increase throughput.
Since the image service is just a proxy and processing layer on top of the existing data, there is no risk that the image server could destroy or lose data. The data is persisted at a lower level and the image server doesn’t require permissions to delete data. If the service goes down, the problem is that the data is inaccessible until it is restored. If the service itself doesn’t have to handle persistent storage (using an object store instead), then we don’t have to worry about persisting previous results between deploys.
6 Further considerations¶
6.1 Deployment and Operations¶
Since both the image service and the database service don’t require a lot of state, we can easily run multiple copies of all the services at once. These different instances can be different versions and isolated from each other.
This means that to help do upgrades and deployments, we could easily keep the current version running, deploy the new version and do checkouts and testing, then update the nginx ingress rules to point to the new version. This means we don’t have to take downtime to do a deployment.
The state that may make this tricky are the requests that are queued or in-flight, and the history database itself. For requests that are already satisfied, but having their data put in the object store, the results are still accessible even if the service instance that created it might be taken down.
For requests that are queued, they will simply be delayed. For in-flight requests, we can either drain the worker pool (stop taking new requests, finish what you have), or just kill the workers and have an automatic retry for failures that look like they are technology related (disk issues, network reconnects, etc.).
If we want to do none of these, any user or client can simply re-run the query and we will start over again from scratch.
6.2 Testing¶
Testing the services should be fairly straightforward. There are a few types of testing we need to consider:
- Standards compatibility testing - we need to be compliant to the standard.
- Query testing - testing normal paths and edge cases via specific targeted queries.
- Robustness - ensuring our services operate normally and have good availability.
Due to the nature of being a generally stateless proxy, most tests for testing standards compatibility and individual queries can be done anywhere, and are easily repeatable and reproducible. While some of these standards are complex, they generally don’t have a lot of API surface area (endpoints to call). Combined with being stateless, this means we should be able to easily reproduce issues if we have the query string, even on another test instance from production.
For standards testing, at least against TAP, there is taplint, which should be able to help test against the standard.
For query testing, we should try to run some queries that we think will be common for the use cases of the science platform. As people report issues using the platform, we should be logging the query string and result codes. Any queries that fail due to some bug should be investigated, and that particular query string can be added to a list of tests to run to check for regressions. Since each test is essentially just a query, and making sure the response hasn’t changed, we can use a hash of the results, or check the results for particular fields to validate that it is the same.
One type of testing that may have timing issues in it is the general robustness. We need to make sure things like deploys and upgrades work without issue, and hopefully, without downtime. As nodes go down in our kubernetes cluster, or we scale up or down, we may run into bugs and issues, especially with kubernetes like things. These should be worked through with help of NCSA or the kubernetes admins.
6.3 Retention Policy of Results¶
Currently the retention policy for results has not been defined and no requirements have been proposed. Obviously we need to retain results at least until the user has had a chance to retrieve them. Once the result has been obtained, the user may need to retrieve it again for some reason. Given that it may have taken hours to comb through the large LSST dataset, we might not want to throw away that result so quickly.
On the other hand, with large (5 GB) result files, we can’t just keep all the results of all time. There needs to be a balance.
There are some obvious ways of doing this:
- Have enough disk space to comfortably have a window of X days before your result is deleted. X could be 5 days, a month, etc. We probably won’t know until we know the usage pattern, as if there are a lot of queries in a short time, we might exhaust our space before X days is up.
- Keep X GBs of past results. This way you can expire results that are the oldest first, and keep our cache at a constant size. This implies that all the users are in the same bin, so if one user is making most of the queries, they will take most of the cache. But assuming they are using all these query results for doing good things, that is probably the most efficient way.
- X GBs per user. We could do this, but it’s likely that we won’t have a disk big enough to have all users at full quota. Like a gym, we have to assume some people won’t use their allotment.
It’s likely we’ll have some kind of combination of business rules of these strategies, and we want to keep this as an operational sidecar script that can be easily tweaked and run by hand if necessary. If we use an object store, this can easily be run with appropriate credentials against the object store to clean it out on demand, or even hand pick certain results to delete.
Note
These are just guesses. Determine actual requirements here.